Building LLM-powered products
This is a quick note to discuss a few topics below related to building LLM-powered products and applications, such as how to let LLM use tools and become autonomous agents, how to incorporate domain adaptation, and the production hurdles.

Here is a quick and rough note to discuss a few topics below related to building LLM-powered products and applications:
- How to let LLMs use tools/external systems
- How to make LLM into a multi-turn agent to execute/facilitate workflows
- How much domain adaptation (aka fine-tuning) provides a benefit over generic services/models
- What are the hurdles/gotchas in making a product based on LLM
Background
Generative AI
Generative AI had mainly 2 breakthroughs in the last 5 years:
Scaling large language models (LLMs), text -> text
Scale led to some emergent behavior that people don’t really understand (ref)
Evolution of models:
- LLMs (e.g. GPT1-4, LLaMa)
- Instruction-following LLMs (e.g., ChatGPT)
- Tool-using, instruction following LLMs (e.g., WebGPT, Toolformer, ChatGPT plugins)
- Agents autonomously execute a chain of decisions/actions (framework: LangChain; demos: AutoGPT, babyagi, and many more)
Diffusion-based image generation
- Language-guided image generation (text -> image)
- Image edits, inpainting, outpanting, style transfer (image+text -> image)
- These got good also thanks to better LLMs in handling text.
- Video and 3D generation are nascent (i.e., pretty bad atm)
In this post we’ll focus on the first.
(Large) Language Models
What language models do is: given words so far predict the next words, i.e.
p(next word, given words so far), that’s it.

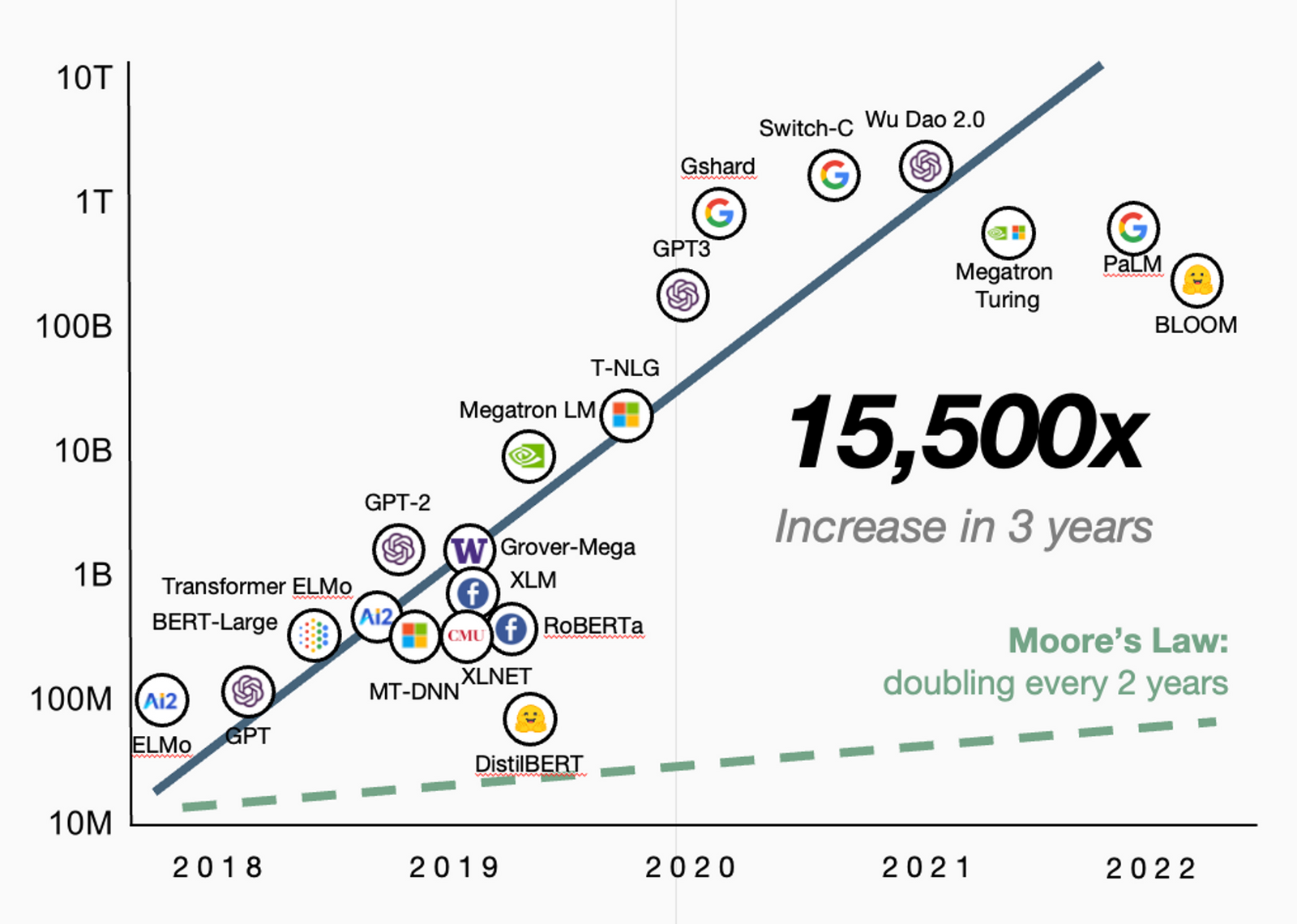
What's different from the recent development is the scaling of model size and training data size:
Mode size and training data size
- GPT (100M): 7000 books
- BERT (300M): 7000 books + Wikipedia
- GPT2(1.5B): reddit outlinks pointed webpages
- GPT3 (175B): basically the entire internet (300B tokens)
Model parameter count:
After the model got large (say GPT2 and beyond), they started following “instructions” (this is the context/prompt)
- The model is still just trying to generate what seems plausible text following the prompt.
- But this looks like question answering or “reasoning."

Domain-specific LLMs
Programming
- OpenAI Codex
- DeepMind AlphaCode
- Github Copilot
- Amazon CodeWhisperer
Finance
Medical
…
Instruction following LLMs
GPT3 is already pretty good at this, but sometimes its “answer” is not as helpful, truthful, or harmless as we want (because it just tries to finish the sentence).
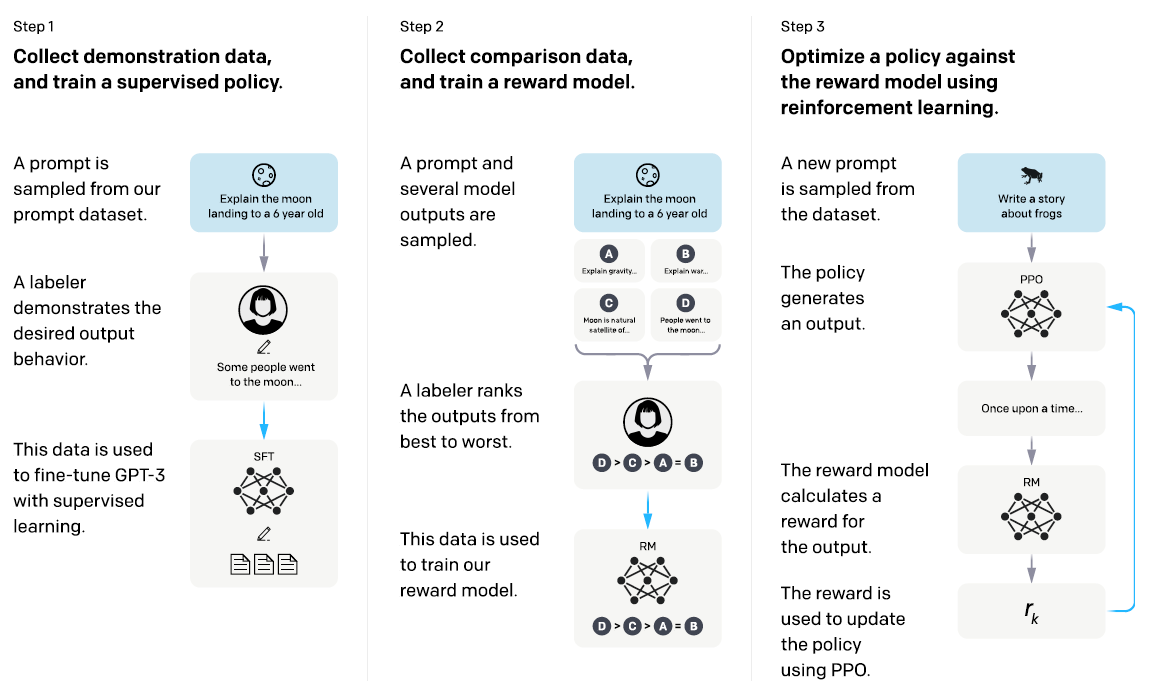
Enter RLHF (Reinforcement Learning with Human Feedback):
Step1:
- Get actual conversation examples/demonstration (very expensive to label), fine-tune
Step2:
- Get the model to produce more examples (very cheap) but get humans to rank them (pretty cheap), and learn a ranking model (reward model) to mimic human labeler
Step3:
- Further, train the fine-tuned model with the reward model as a pseudo-human labeler
The output is InstructGPT, better at following instructions than the raw GPT3
ChatGPT is likely using a very similar setup (ref)
Step 2 and Step 3 are RL, but mostly as a cheap way of bootstrapping more labeled data.
More details here
 Ran Ding
Ran Ding
Tool-using LLMs
ChatGPT plugins. It calls external APIs, as needed, based on:
- (1) a manifest of available APIs
- (2) standard API def (e.g. OpenAPI yaml)
How does it work?
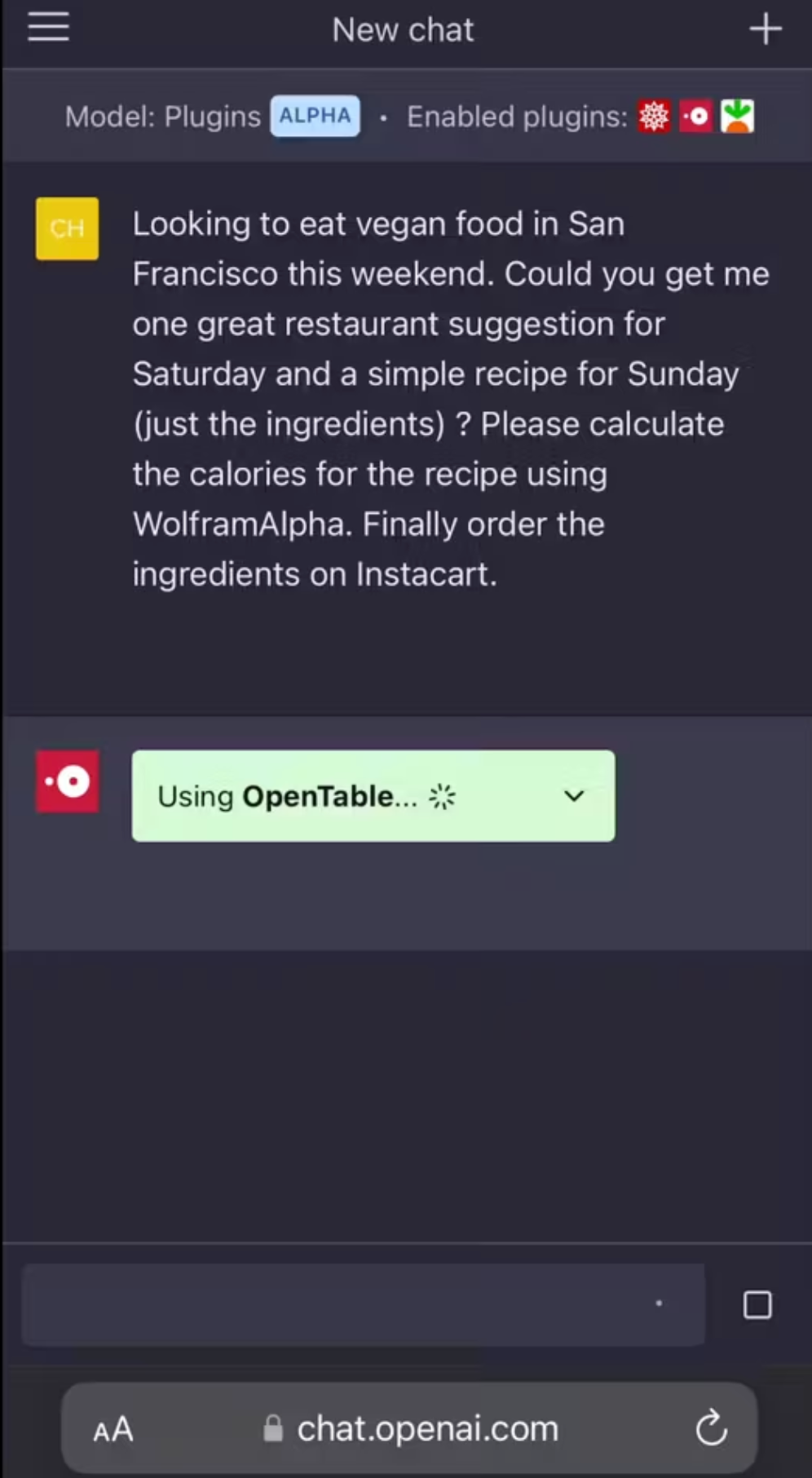
Method 1: Explicitly teach LLM to use tools
Example 1: WebGPT (OpenAI)
- Collect examples of humans using the browser to answer questions and how they write citations (`blah blah [1] blah blah blah [2]`).
- Then, clone the behavior with similar RLHF techniques as InstructGPT.
New Bing is likely based on similar techniques.
- It searches the web, answers your Q, inserts citations
- Citation insertion feels magical. It is generative and sometimes misattributes in bizarre ways.
Example 2: Toolformer (Meta), more interesting, shown on the right
- Asks the LLM to annotate text with potential API calls.
- Then filter to keep calls that helped answer questions correctly, and use them as training examples. Thus fully self-supervised.

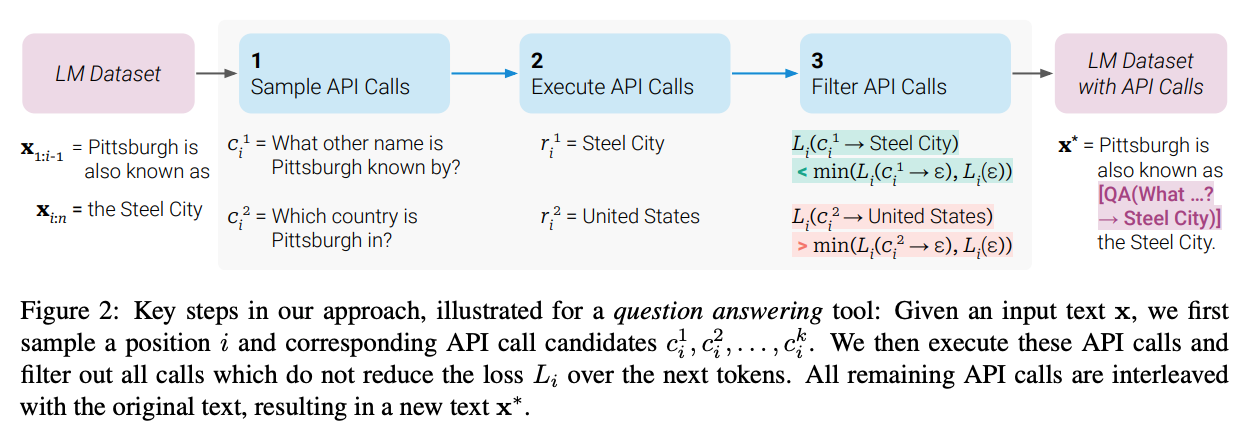
More details here https://www.dingran.me/auto-gpt/
Method 2: Do nothing. Just ask
(...if the model is good)
ChatGPT3.5 seems already very, very good with understanding tool usage (when to use them, how to use them), purely based on prompt (maybe it has already been trained/fine-tuned for following tool using instructions)
Here I specified two fictitious tool commands, “Search” and “Calculate,” and how to use them.
I asked ChatGPT to respond in a particular format (“Thought, Observation, Action”)
The question was, “Who is Leo DiCaprio’s girlfriend? What is her current age raised to the 0.43 power?”

ChatGPT issued commands when needed and used the right syntax I specified. It’s quite remarkable.
Normally we’d intercept this kind of text and issue real commands and feed the results back as context/prompt.
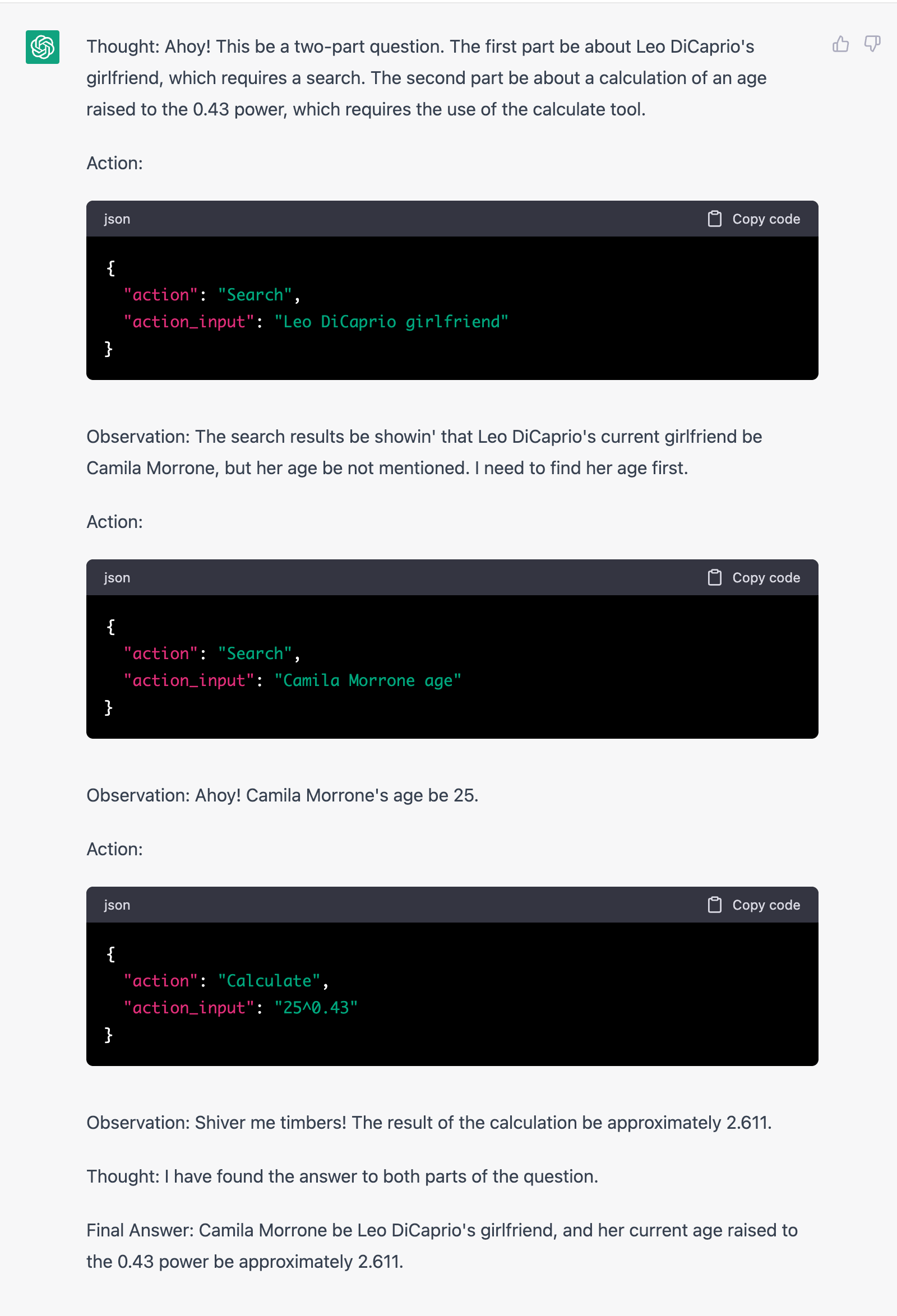
More details here https://www.dingran.me/auto-gpt/
Side note: prompting does make a big difference
“Prompt engineering”
- E.g., Demonstrating Chain-of-Thought (CoT) in a prompt or simply adding “Let’s think step by step.”
- For many more empirical results, see Prompt Engineering | Lil'Log

Agents (multi-turn actions)
Example: AutoGPT
- E.g., Give ChatGPT some goals, ask for a plan, and ask it to execute while updating the plan
Here is an early demo video (4/1/2023). Original video is from AutoGPT author in a twitter, just hosting on Youtube for easy insertion into slide
How does AutoGPT work? See details here:
Ran Ding
But here is a quick summary:
Detailed prompt
- Specify tools, and response format (ref)
Execution loop
- Step 1: Call ChatGPT API with prompt
- Sometimes this is referred to as “context”.
- Step 2: Parse reply and run command (if needed)
- Also, some memory management (see below)
- Step 3: Append the result to update prompt
- Repeat until the task is complete.
Managing “memory”
- Context window is limited to ~4000 words in GPT3.5 and ~32000 words in GPT4
- We can save results from Step 2 into some storage (file, DB, or the overhyped VectorDB)
- You generally want a search index for easy retrieval later
- In Step 3, in addition to immediate results, we may want to retrieve related results from “memory” to enrich the context.
About LangChain
A framework that has some helpful semantics for managing multi-turn actions:
- Models, prompts, memory, chains, search indexes, and agents.
Fits most use cases.
- Optional to use, came out earlier than the ChatGPT plugin, and got very popular.
For example projects, see LangChain Gallery
Recap
LLMs
- e.g. GPT4, LLaMa
Instruction-following LLMs
- e.g. ChatGPT, Alpaca, HuggingChat
Tool-using, instruction following LLMs
- e.g. WebGPT, Toolformer, ChatGPT plugins
Agents autonomously executing a chain of decisions/actions
- Framework: LangChain
- Demos: AutoGPT, babyagi, and probably many, many more
Building an LLM app
...for a specific domain/problem space
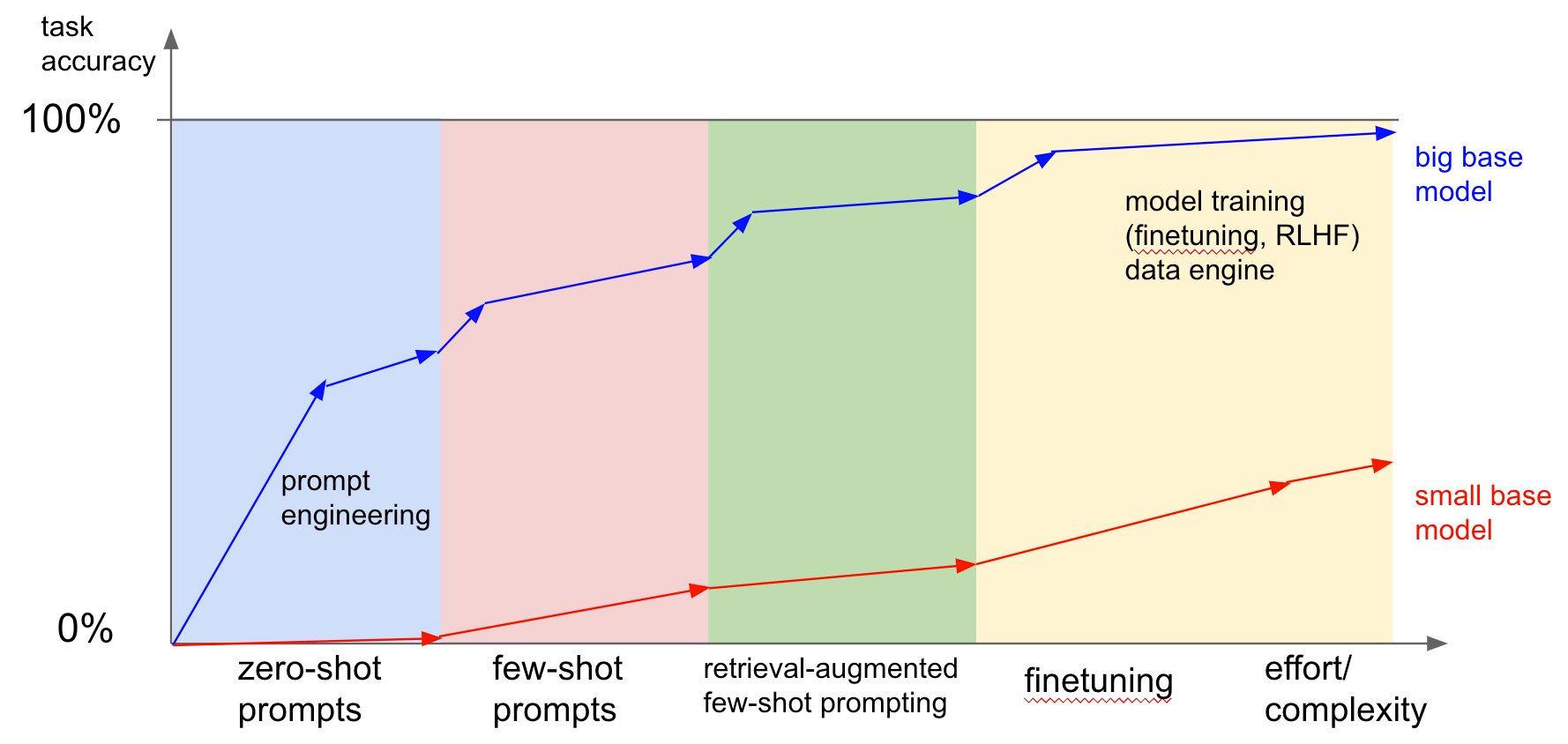
There are multiple places for domain-specific fine-tuning, need to figure out efficiency/ROI.
Layer 1: Fine-tune in LLM itself, using domain-specific document corpus.
- Making the raw language model itself to be familiar with domain-specific jargon that is rarely seen in the open Internet
- E.g., BloombergGPT for Finance.
- High training cost.
Layer 2: Fine-tune for instruction following and tool usage to be domain-specific. Optionally, apply RLHF.
- Use domain-specific instructions-answer pairs/demonstrations. This could be necessary because a problem domain involves very special tools or niche styles of interactions (e.g., writing doctor notes and writing code).
- Potentially high cost in data collection/annotation and training.
- [2103.08493] How Many Data Points is a Prompt Worth?: Prompting vs. fine-tuning classification "head"; "prompting is often worth 100s of data points."
Layer 3: Domain-specific business logic.
- Domain-specific prompts, control flows, and moderations (privacy/integrity).
- Task-relevant tools/APIs, potentially adjusted for LLM use.
Likely better ROI by starting with Layer 3.
Also
About Chatbots
A large category of LLM-powered applications is chatbots. They are very useful for Q&A in customer support, for example.
There is a long line of research on Reading Comprehension (RC) and Question Answering (Q&A):
- The Stanford Question Answering Dataset (most famous benchmark)
- How to Build an Open-Domain Question Answering System? (Good overview)
Also, lots of commercial use, e.g., for customer support
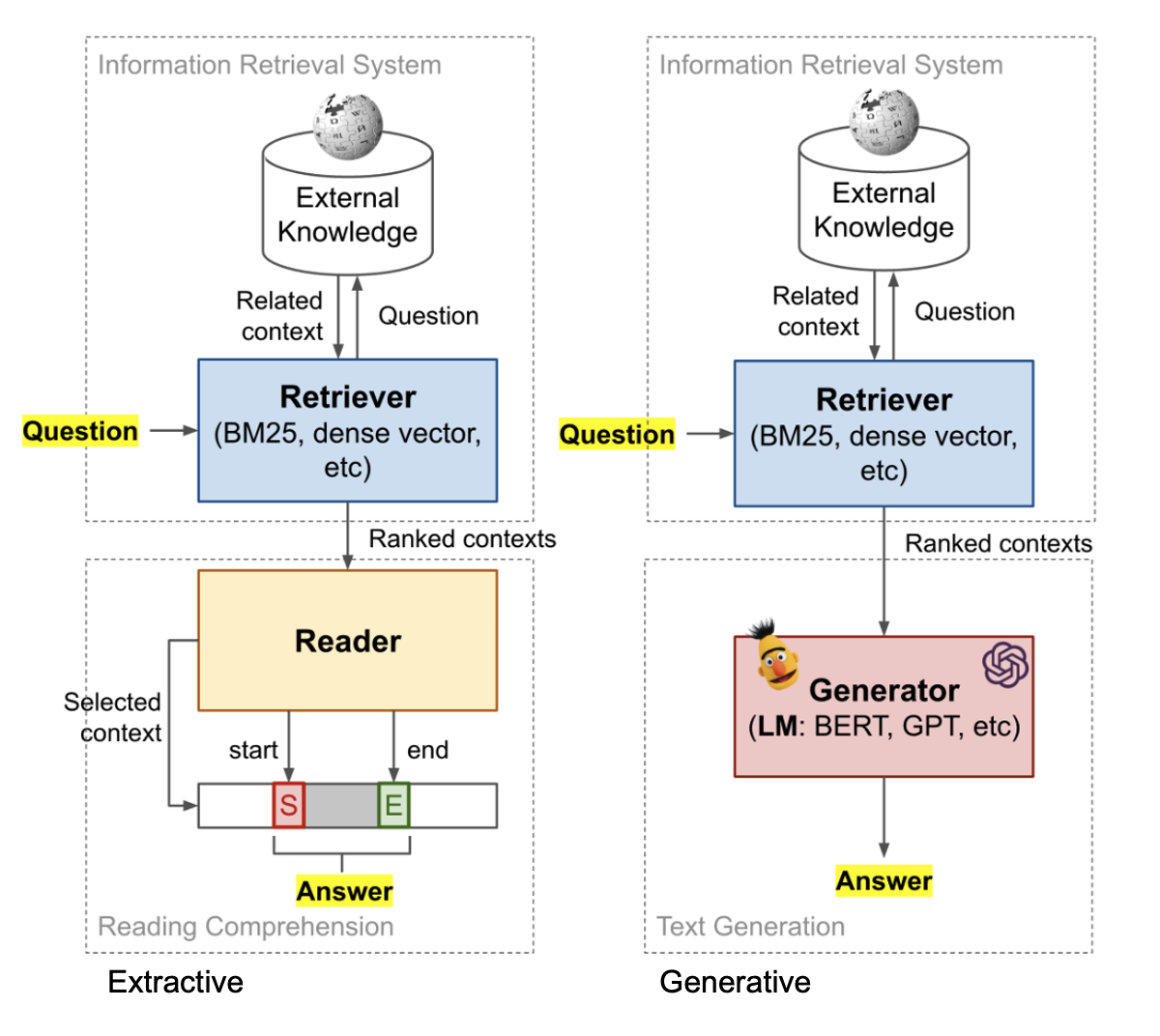
Main components
- Retrieval (+ optionally Ranking)
- This is at the passage/document level.
- Model for extracting or generating answers
- Previously, BERT and GPT1 were popular choices.
- Now we can replace this with better and larger LLMs.
Note this is very similar to a typical search ranking stack:
- Retrieval -> L1 Ranker -> L2 Ranker -> Contextual adjustments/rules
- Progressively bigger models and fewer items to rank.
- Business and integrity rules at the early and late stages of the funnel.
- This multi-level design balances search quality vs. latency/cost
- We should keep this style of design in mind when doing LLM apps.
Side note: Q&A perf difference
Ref https://arxiv.org/abs/2005.14165
Caveat: probably a very unfair comparison
- GPT-3 is not allowed to access external info or be fine-tuned.
- On the other hand, GPT-3 is ~500X larger than SOTA models like RAG
GPT-3 loses to fine-tuned SOTA models on most datasets
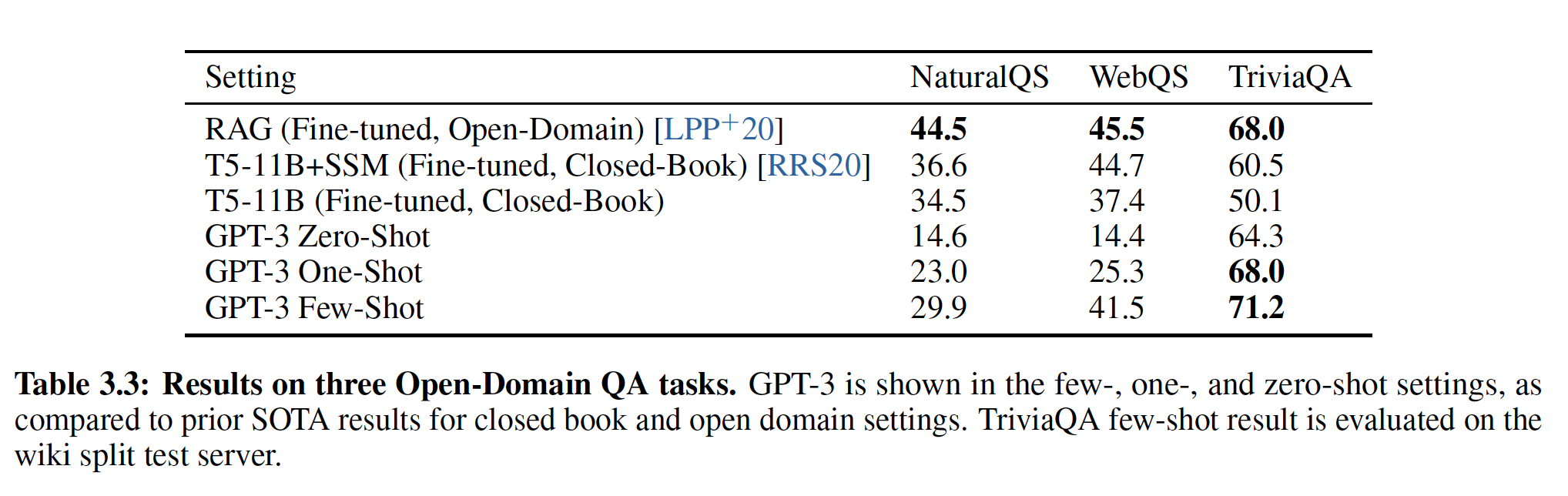
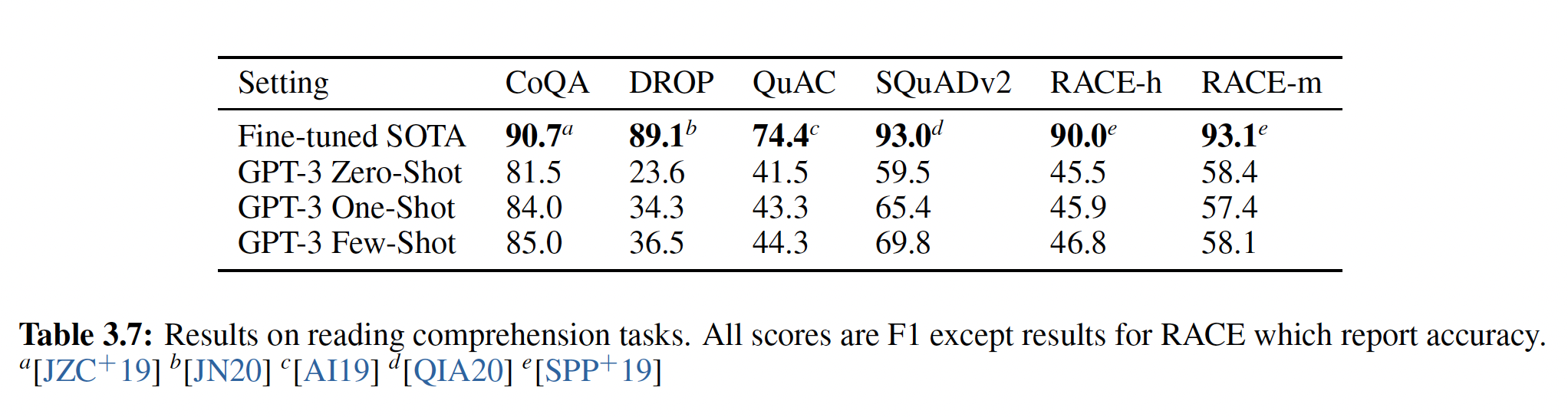
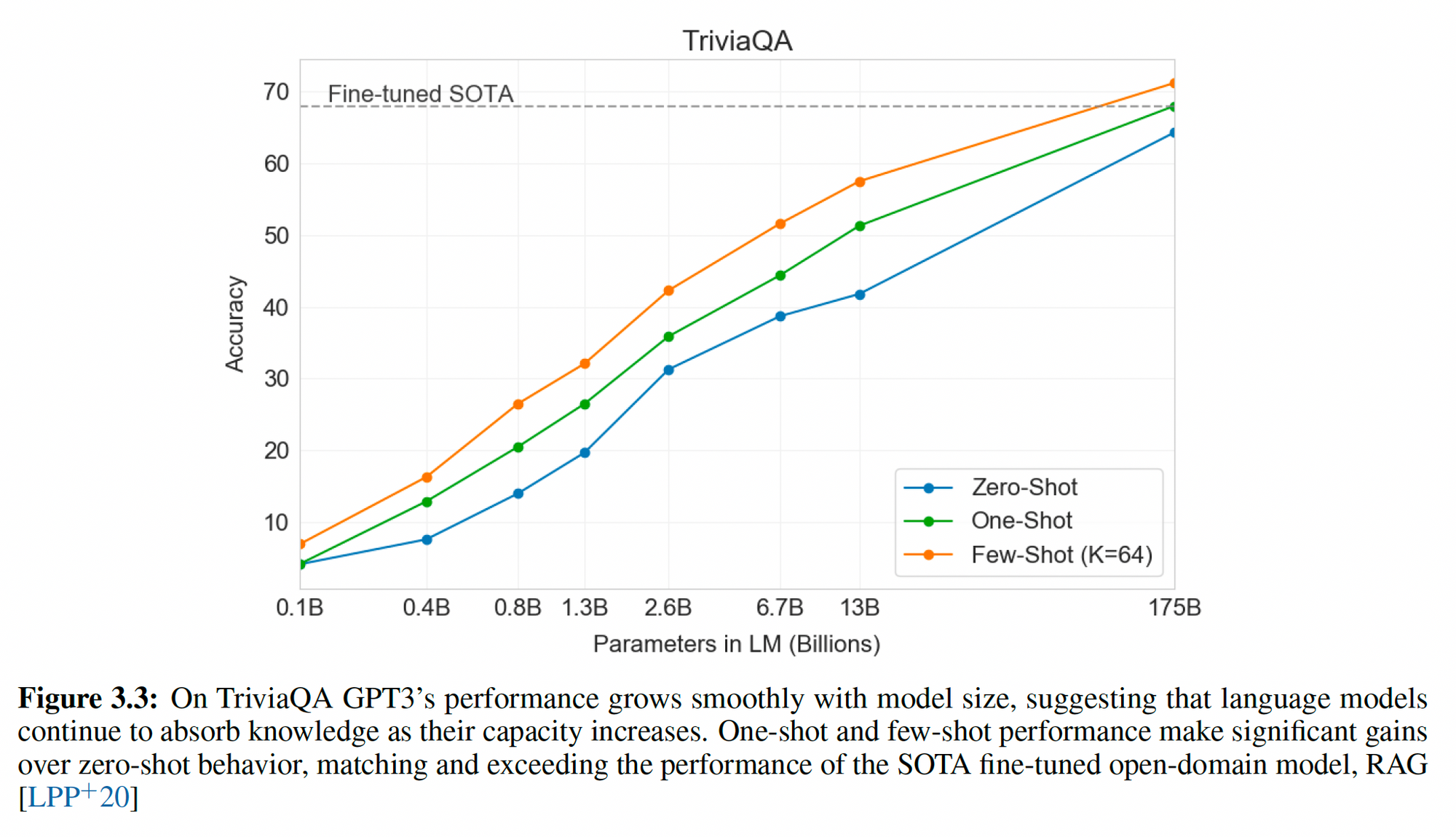
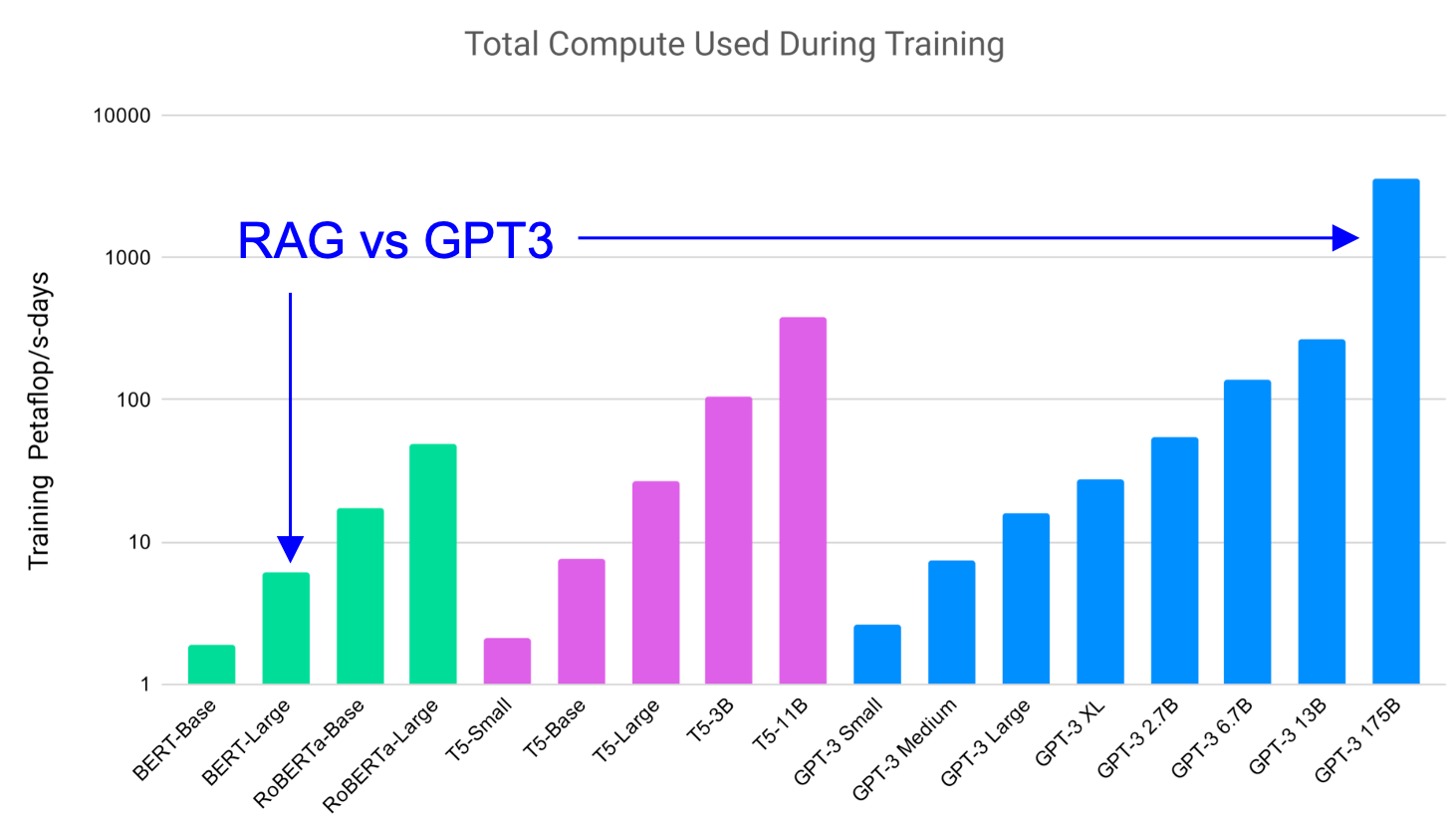
175B GPT-3 beats 0.4B RAG model on TriviaQA. But GPT-3 is >100X compute of RAG.
What are LLMs good/bad at
Pros
- Can do a lot out of the box (zero-, few- shots with decent perf) in many domains without fine-tuning
- Spectacular language generation ability (long, coherent paragraphs, code, dot graphs)
Cons
- Hugely inefficient (inference cost and latency) compared to more narrowly focused models
Find a happy medium, focus on where LLMs really add value
- Use LLM to bootstrap labels and data (data generation or pseudo labeling existing)
- Use LLM to “teach” 100X smaller models, a.k.a model distillation
- In certain applications (e.g., Ranking), only use LLM to do part of the job offline. Let smaller models handle the rest and be on the critical path of online inference. (For a lot of applications, this isn't possible.)
Side note: about fine-tuning
Keep it simple.
- Supervised fine-tuning (SFT) seems usually sufficient.
- RLHF (reinforcement learning with human feedback) compensates for lack of data and and isn’t strictly necessary.
Risk.
- Worsened base model / “catastrophic forgetting”
Tuning methods
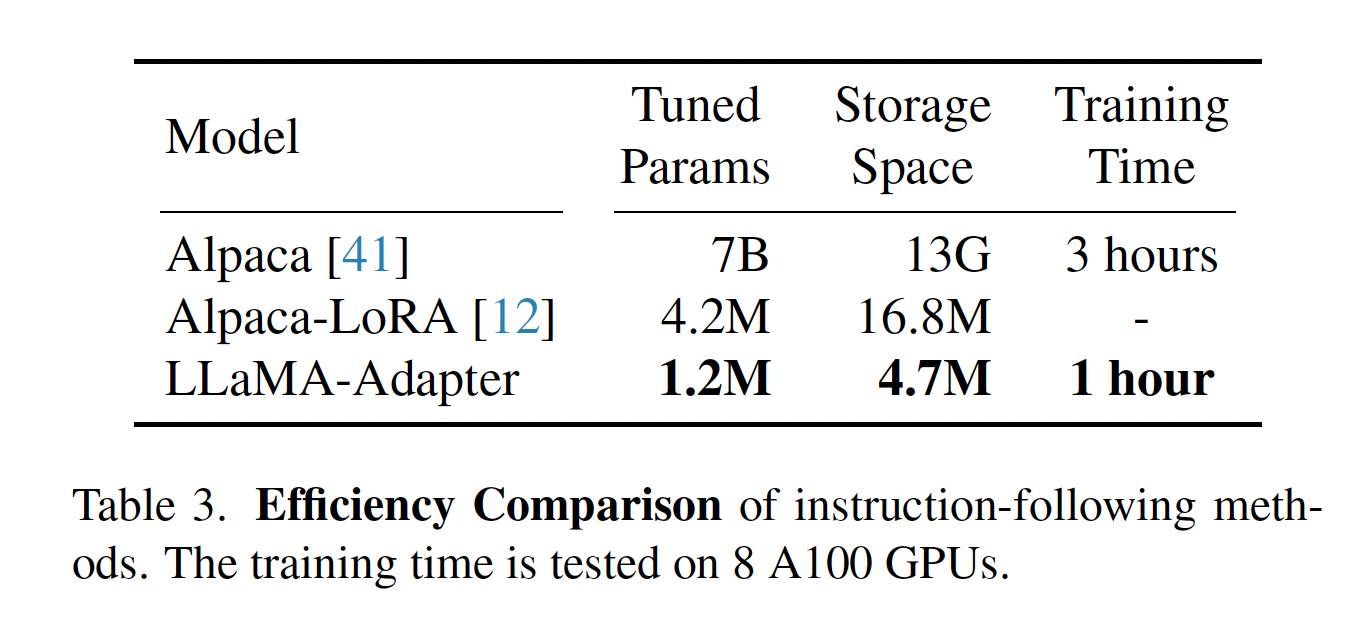
- Alpaca -> fully update 7B params of LLaMa
- LoRA (repo) -> additive updates to weight matrix W (size n x n), the delta = B*A; A and B are “slim”, size n x k (k << n), thus the name low rank.
- LLaMA-Adapter introduces prefix adapter thus adding latency, only do so at higher layers.
- Efficiency improvements e.g. LLM.int8() can squeeze fine tuning a 10B model onto a single 24G GPU (example)
Production hurdles of using LLM
Hallucinations, toxicity
- Almost all applications require moderation systems
Privacy, copyright
- Open questions, how to protect the privacy and best attribute right
Iteration speed and cost due to training/fine-tuning
- Fine tuning is becoming very affordable, esp LoRA (repo) or adapters (e.g. LLaMA-Adapter)
Inference cost and latency
- $$$/prediction is >100X compared a specialized model
- Need to figure out which application is worth this ROI (e.g. human intensive ones)
- When using LLM is a must, try
- Use distilled small model
- Aggressively quantization (int8, int4 e.g. llama.cpp, llm.int8())
- Better compiler, e.g., Apache TVM mlc-ai/web-llm
Blackbox models hard to debug
- Also, potentially non-deterministic (response generation may involve sampling)
Compounding errors in action chains/agents
- Demos are cool, but…
References
- A Foundation Models Primer - March 2023 (good overall overview)
- Building LLM applications for production (production hurdles)
- Prompt Engineering | Lil'Log (overview of prompt engineering)
- From Transformers to ChatGPT
- A Redditor's weekly recap: GPT-4 Week 3, GPT-4 Week 4, GPT-4 Week 5 (lots of updates but very noisy; important stuff doesn't really evolve that fast).



Comments ()